A Process for XML Data Design
Key Players
These are the key players in developing an xml data design:
- Subject Matter Experts (SMEs): these are people that are experts in a subject (domain), but are not necessarily expert at the technologies employed to implement the domain.
- Technology Experts (TEs): these are people that are experts at the technologies, but are not necessarily expert in the subject matter.
- Facilitator: this person is responsible for getting the data specification written. He is a business-minded te. Domain expertise is not required. This person must be comfortable leading a discussion about process and data, must be adept at hiding the complexities of xml while still exposing the hierarchical, cardinality, and basic data type aspects of the data requirements that are intuitive to smes.
- Users, Business-Oriented People: these are users of applications that will use the data, along with business people.
Below is a sequence of steps (i.e. a process) for creating an xml data design.
Step 1: Create a Data Specification
A data specification is a document, written in prose, which describes the data and the relationships between the data. All data implementations - xml schemas, schematron, relax ng, dtds, and others - must derive from the data specification. Further, all data implementations must be traceable back to the data specification. A data specification is the authoritative specification of the data.
The data that is documented by a data specification may be targeted for use as a data interchange format or for use in the management of data within an application. A data specification is focused on the data, not on processes or architecture. Details of how the data fits into the overall system dataflow architecture are to be found in other documents. That said, a data specification is more than just a raw listing of data and definitions (i.e. a data dictionary). A data specification contains descriptions of how the data fits into the overall system, has lots of examples of how the data is used, and shows sample forms of the data.
When creating a data specification it is important to get inputs from a diverse set of people. Different people have different perspectives on the data. Never assume that any one person has the whole picture. Get inputs from smes, tes, users of applications that will use the data, as well as business people.
The first step in creating a data specification is for the facilitator to bring together smes, tes, users, and business people for the purpose of creating a data specification. Although "processes" is out-of-scope for a data specification, sometimes it's important to agree on processes before discussing the data. Conversely, sometimes discussing data first helps people recognize a process-alignment issue.
The facilitator interviews the smes. The te listens in on the discussions to come up-to-speed on the domain. He may be able to provide early alerts of possible implementation problems. The users and business people keeps the meeting grounded in practical application needs. The facilitator writes the data specification; ideally, it is written in real-time, with everyone in the meeting watching on an overhead projector (or, if it is a virtual meeting, everyone sees the document being written on their computer screen).
While developing the data specification it is important to be careful of loose, ambiguous terminology. The data specification must provide clear, unambiguous prose describing the data.
Avoid performance discussions. That belongs in another activity, not this one.
Depending on the amount of data to be specified, it may take just several hours to create a data specification, or it may take several hundred hours.

Example: A Book Data Specification
An expert on books (i.e. a book sme) is interviewed by a facilitator, as a te, users, and business people chime in. The result is a "book data specification." It's a detailed, complete document, containing prose on what a book is and the data that characterizes a book and the relationships among the data. Here's a table which succinctly summarizes the book domain's data and hierarchy:
Book
Author ..... String
Title ...... String
Date ....... Year
ISBN ....... Sequence of digits, dashes, and 'x'
Publisher .. String
Step 2: Create One or More Implementations from the Data Specification
The te carefully rereads the data specification to make sure he has a thorough understanding. From it he creates one or more implementations, along with sample xml instance documents. For example, he may create an xml schema plus a schematron schema. Or, he may create an rdf schema.
An implementation may or may not be a 1:1 mapping of the data specification. For example, a data specification may describe the data in a traditional parent-child format, whereas the implementation may be an rdf graph. Or, an implementation may be incorporated into a broader activity which requires a generalization of the data. For example, book data that is specified in a book data specification may be incorporated into a larger multimedia interchange format, perhaps requiring "Book" to be generalized to "Product."
If there is not a 1:1 correspondence between an implementation and the data specification, then there must be a way to map between the implementation and the data specification. This is important for traceability.
The te must take into consideration the kinds of processing that applications are expected to perform on the data. Certain data designs may make processing horribly inefficient, while other designs can make processing very efficient.
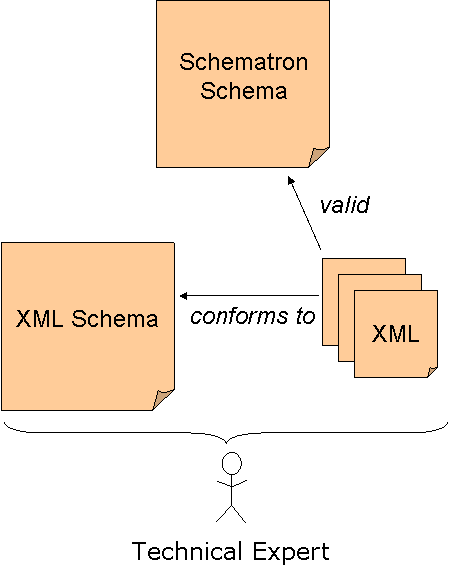
Example: Book XML Schema and XML Instances
The book data specification is handed off to a te for him to create an xml data implementation; specifically, an xml schema.
The xml schema declares a <book> element that is composed of <author>, <date>, <isbn>, and <publisher> elements. Sample xml instance documents are then created and validated against the schema.
Step 3: Review the Implementation
The te shows and describes the implementation(s) and sample xml instances to the group (smes, users, business people, and facilitator). The group is now able to see how the data specification was interpreted by the te and evaluates the resulting structures. The te seeks clarification on any data and data relationships that were found to be unclear during development of the implementation(s).
Step 4: Clarify and Adjust the Data Specification
Based on the discussions in Step 3, adjustments are made to the data specification.
Step 5: Iterate
The te makes revisions to the implementation(s) based on the updated data specification, and creates new sample xml instance documents. The new implementation(s) and samples are brought back to the group. Updates are made to the data specification.
Repeat as often as required.
Translations
Thanks to Daniela Milton for translating this document to Swedish:http://www.autoteilexxl.de/edu/?p=2138
Acknowledgements
Thanks to the following people for their input to this document:
- Len Bullard
- Kurt Cagle
- Marcus Carr
- Chin Chee-Kai
- Roger Costello
- Jonathan Doughty
- Fraser Goffin
- Jeff Grief
- Erick Hagstrom
- Peter Hunsberger
- Michael Kay
- Robert Koberg
- Frank Manola
- Bob Natale
- Dave Pawson
- Simon St.Laurent
- B. Tommie Usdin
- Jim Wilson
Translations
Daniel James translated this article to Spanish. The translation may be found at this URL: https://spainevo.blogspot.com/2019/07/un-proceso-para-el-diseno-de-datos-xml.html.
Ashna Bhatt has translated this article to Thai. The translation may be found at this URL: http://eduindexcode.com/a-process-for-xml-data-design/.
Last Updated: July 1, 2019