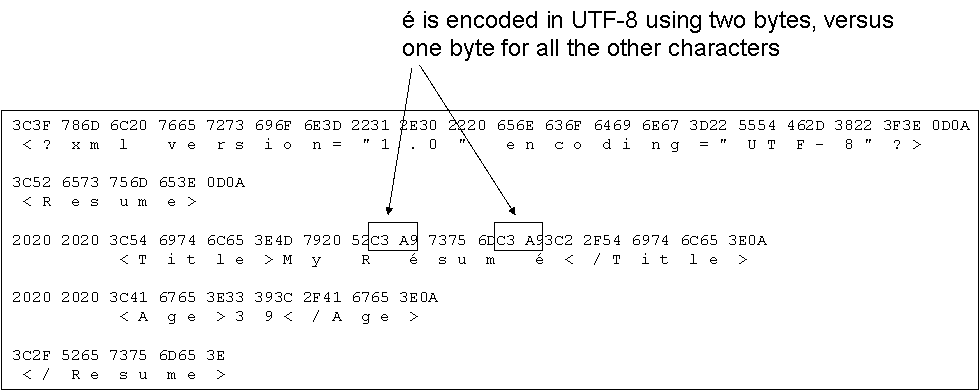
Here is a simple XML document. Most of its characters are ASCII, but there is one non-ASCII character, the é character:
<?xml version="1.0" encoding="UTF-8"?>
<Resume>
<Title>My Résumé</Title>
<Age>39</Age>
</Resume>
In UTF-8 all ASCII characters are encoded using one byte. Non-ASCII characters are encoded using 2, 3, or 4 bytes. Below is shown the byte values for each character in the above XML document. Notice that the é character uses two bytes whereas all the other characters use one byte.
The Unicode code point of é is: U-00E9
All code points greater than or equal to U+0080 require more than one byte.
Hex E9 = decimal 233, which is binary: 11101001
Take the low six bits from the binary and replace the z's in this: 10zzzzzz. Take the upper 2 bits from the binary and replace the y's in this: 110yyyyy
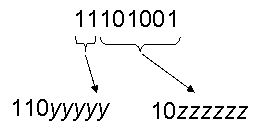
Thus we arrive at these two bytes: 11000011 10101001
These bytes correspond to hex C3 and hex A9.
Thus, é is encoded in UTF-8 as: C3A9
The Unicode code points of the other characters (e.g. M y R s u m) are all less than U-0080, and so the UTF-8 encoding of those characters uses only one byte for each character.
This online tool allows you to see the hex values for UTF-8 encoding, UTF-16 encoding, and others: http://people.w3.org/rishida/scripts/uniview/conversion.php
The following people contributed to the creation of this document:
Last Updated: September 28, 2007